They are not!
CPUs typically have higher clock speeds than GPUs. For instance, AMD’s Ryzen processors nearly reach 4 GHz, while NVIDIA’s GeForce 40 series barely reach 2.5 GHz. Although clock speed is a factor, it’s not always the most important aspect of a chip. Often, the capability to handle large volumes of computation simultaneously outweighs the processing speed.
The answer is straightforward:
GPUs excel in computing more data per tick of their clock in comparison to CPUs, thanks to their multiple cores and SIMD instructions. Initially, custom shader programming had to be used for general-purpose computing on GPUs, but shortly later it could be made with CUDA on NVIDIA’s cards.
In the following sections, let’s dive deeper into the highlighted terms (in bold) from the previous paragraph.
Clock

Every computer depends on a quartz crystal oscillator. Yes, the same “quartz” we find printed on physical clock backgrounds.
Quartz crystals are piezoelectric, which means they have a unique property: when electricity is applied to the crystal, it expands, and when it contracts, an electric charge is released:
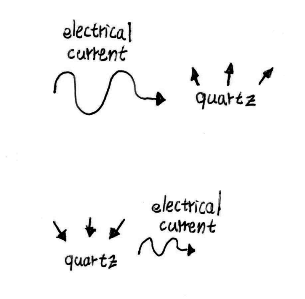
When this setup is put in a closed circuit, together with an amplifier for charging up the electric current coming from the crystal, we have a reliable ticking clock:
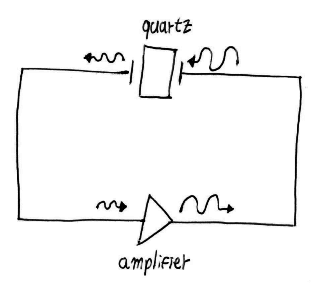
Modern computers require clocks because they operate as synchronous circuits. Each clock tick synchronizes all circuit components, ensuring they advance to the next computation step together.

But there’s only so much you can go by speeding up the clock. Increasing clock speeds beyond a certain point can lead to significant heat generation. Heat can degrade performance, shorten component lifespan, or cause system failures. Landauer’s principle states that there’s a limit to how fast computations can be performed without increasing power consumption and heat dissipation exponentially.
Cores

After reaching the limit on how fast the clock can go, what else can we do?
One option is to multiply the processing units available on the chip, going from a single to multiple cores. Cores are individual processing units, allowing the computer to handle different tasks in parallel.
However, adding more cores comes with both software and hardware costs.
On the software side, the operating system and multi-threaded programs must manage the synchronization of tasks processed separately, which can be a difficult problem to solve.
On the hardware side, each core is a fully capable processing unit, so having multiple cores makes the chip significantly more complex.
Consider the following image of an old Intel 8086 processor with a visible die:

Zooming in on the die:
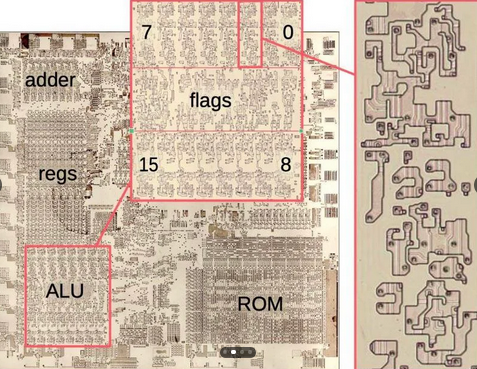
Zooming in further we can see a NOR gate:
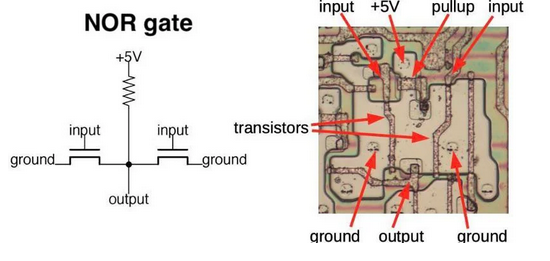
With the picture in mind, imagine the complexity involved in creating a multi-core chip with an instruction set containing over a thousand instructions, like the x86-64 ISA. Now, compare that to the 132 instructions of NVIDIA’s PTX instruction set.
A simpler instruction set allows for more cores on a chip. This is evident when you consider that a Ryzen 7 has 8 cores whereas an RTX 3060 contains over 3,500 cores.
SIMD
SIMD (Single Instruction, Multiple Data) allows the execution of an operation on multiple data elements simultaneously, doing many calculations on one tick of the clock:
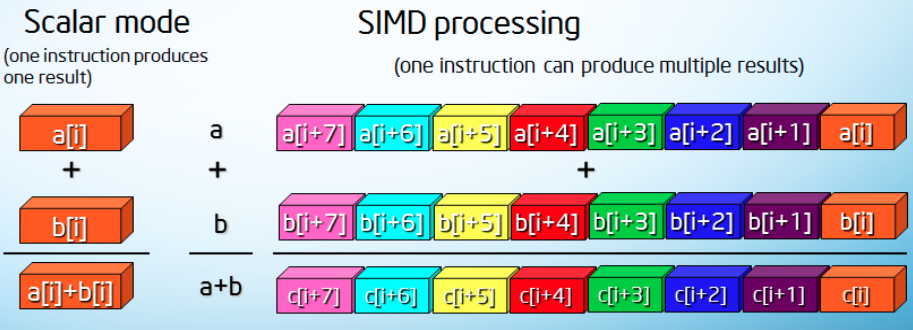
SIMD is common on GPUs but it can be found on CPUs too, through extensions like AVX. However, GPUs take it a step further by introducing a similar concept but operating on threads instead, called SIMT (Single Instruction, Multiple Threads).
Shaders
Shaders are small programs used in graphics to create effects such as lighting and textures influencing how objects appear on a screen:

Introduced by NVIDIA alongside the GeForce 3 graphics cards in 2001, programmable shaders marked a significant advancement in rendering technology:
With the GeForce3 and its nfiniteFX™ engine, NVIDIA introduces the world’s first programmable 3D graphics chip architecture. (…) The addition of programmable Vertex Shaders, Pixel Shaders, and 3D texture technology to consumer graphics processors shakes up the PC graphics market—visual quality takes a quantum leap forward.
Beyond their graphical origins, shaders have found utility in scientific computing. Developers in this field discovered that shaders could harness the parallel processing capabilities of GPUs. This allows them to handle massive computational tasks efficiently, even if the results aren’t meant to be rendered.
CUDA
Innovating yet again, NVIDIA introduced CUDA in 2006, a platform that extends GPU usage beyond graphics to general-purpose computing tasks. This development catalyzed breakthroughs in fields like deep learning and scientific research.
To illustrate, here’s an example of summing vectors with CUDA:
#include <stdio.h>
#include <stdlib.h>
#include <cuda_runtime.h>
#include <cublas_v2.h>
// Function to check and handle CUDA errors
void checkCudaError(cudaError_t status) {
if (status != cudaSuccess) {
fprintf(stderr, "CUDA error: %s\n", cudaGetErrorString(status));
exit(EXIT_FAILURE);
}
}
// Function to check and handle cuBLAS errors
void checkCublasError(cublasStatus_t status) {
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf(stderr, "cuBLAS error: %d\n", status);
exit(EXIT_FAILURE);
}
}
// Function to print vectors
void printVector(float *vector, int size) {
printf("[");
for (int i = 0; i < size; i++) {
printf(" %g", vector[i]);
}
printf(" ]");
}
int main() {
// Vectors in RAM
float ramVectorA[] = {1.0f, 2.0f, 3.0f, 4.0f};
float ramVectorB[] = {5.0f, 6.0f, 7.0f, 8.0f};
float ramVectorResult[4];
// VRAM pointers
float *vramVectorA, *vramVectorB, *vramVectorResult;
const int LENGTH = 4;
const float alpha = 1.0f;
// Allocate VRAM memory
checkCudaError(cudaMalloc((void**)&vramVectorA, LENGTH * sizeof(float)));
checkCudaError(cudaMalloc((void**)&vramVectorB, LENGTH * sizeof(float)));
checkCudaError(cudaMalloc((void**)&vramVectorResult, LENGTH * sizeof(float)));
// Create cuBLAS handle
cublasHandle_t handle;
checkCublasError(cublasCreate(&handle));
// Copy data from RAM to VRAM
checkCublasError(cublasSetVector(LENGTH, sizeof(float), ramVectorA, 1, vramVectorA, 1));
checkCublasError(cublasSetVector(LENGTH, sizeof(float), ramVectorB, 1, vramVectorB, 1));
// Perform vector addition: vramVectorResult = alpha * vramVectorA + vramVectorB
checkCublasError(cublasSaxpy(handle, LENGTH, &alpha, vramVectorA, 1, vramVectorB, 1));
// Copy result back to RAM
checkCublasError(cublasGetVector(LENGTH, sizeof(float), vramVectorB, 1, ramVectorResult, 1));
// Print result
printVector(ramVectorA, LENGTH);
printf(" + ");
printVector(ramVectorB, LENGTH);
printf(" = ");
printVector(ramVectorResult, LENGTH);
printf("\n");
// Clean up
checkCudaError(cudaFree(vramVectorA));
checkCudaError(cudaFree(vramVectorB));
checkCudaError(cudaFree(vramVectorResult));
checkCublasError(cublasDestroy(handle));
return 0;
}
Compiling and executing it:
$ nvcc -o vector_sum vector_sum.cu -lcublas
$ ./vector_sum
[ 1 2 3 4 ] + [ 5 6 7 8 ] = [ 6 8 10 12 ]
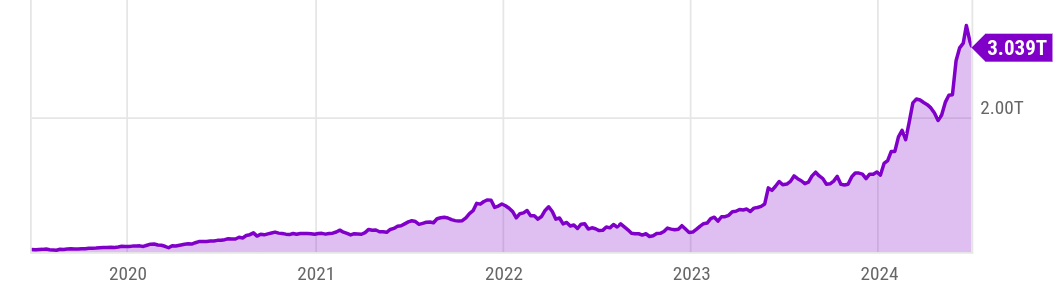
The bet paid off. Fueled by the recent deep learning advancements, it’s no surprise that NVIDIA has emerged as a leader ]in its industry and it’s currently poised for the title of the world’s most valuable company, with a market cap of over $3 trillion:
Sources
- Landauer’s principle
- Piezoelectricity
- Quartz Crystal Design and Oscillator Basics: Lightboard Instruction
- AEN Multicore’s meeting at Minatec, Grenoble.
- The Intel 8086 processor with the x86 architecture.
- x86 and amd64 instruction reference
- Parallel Thread Execution ISA Version 8.5
- Custom Stylized Shader - Cartoon
- NVIDIA Unveils CUDA – The GPU Computing Revolution Begins
- Nvidia is now the world’s most valuable company