“Token” is a remarkably flexible word, at least to a non-native speaker like me. And it’s idiomatic too, it’s present in common expressions such as “by the same token” or “as a token of my gratitude”.

Loosely defining it, a “token” is a (tangible or abstract) symbol of something, like a piece in a game board. More often than not, it also refers to something exchangeable, like a gift card. Sometimes it may even be private, like a banking digital token (anyone remembers the physical ones?).
Tokens in natural language processing
When processing a corpus of text, it’s necessary to be thoughtful of what is the smallest unit of what you are processing. Should we break the text, process, and understand it, word by word? Subwords? Maybe as granular as possible, all the way down to single characters?
The smallest chosen unit is normally called a token.
Tokens in small language models
The most basic language models usually take the route of using character-level n-grams as its tokens (or as it vocabulary if you prefer).
The process is simple. Let’s say n = 3 for our (character-level) n-gram. Here are the 3-grams in the word “godzilla” (with overlapping 3-grams):
- god
- odz
- dzi
- zil
- ill
- lla
Now break every single word in the corpus like this. Assign an unique numerical value for each, making a lookup table. There you go, this mapping of values can now be used as a vocabulary to process this corpus.
Ultimately, training a tokenizer produces a vocabulary that, along with its tokenization rules, can be used at inference time as a token lookup table to convert input text (strings of characteres) into tokens (typically scalar numerical values, like an enumeration):
- “god”: 1
- “odz”: 2
- “dzi”: 3
- “zil”: 4
- “ill”: 5
- “lla”: 6
And vice-versa. There should be a mapping for both directions.
On the model input, the input string will be encoded into a (scalar) numerical value, which is what machine learning models manipulate.
On the model output, the outputted (scalar) numerical value will be decoded into its characters, which is comprehensible for human beings, the output’s target.
Before we move on, we also have mention that models can be word-based n-grams too. However, this approach poses a challenge because the number of words in a language is extremely large. It’s even worse if you are dealing with internet content, not only things can get multilingual, but it can contains slangs and jargons, emoticons, emojis, and more. The sheer number of possible word combinations, that might just not appear in the dataset, is too great. This leads to an undesired sparsity. It’s cursed.
Tokens in large language models
With LLMs, which are models trained on a vast and diverse corpus of text where any Unicode character can go, the n-gram approach starts to look naive. Imagine how big that vocabulary would be. We need a clever algorithm, that:
- Keeps the number of unique tokens in the vocabulary not too large (hard to compute) but not too short (hard to embed meaning).
- Make sure the token is actually common, not dedicating (and ‘wasting’) a position in the vocabulary for a value that will be barely used.
- It’s fast to compute, since it will be called countless times both on inference and training.
Let’s take a brief look at a common tokenization algorithm below.
Byte Pair Encoding (BPE)
One of the most commons implementations is Byte Pair Encoding, or BPE for short. It’s entire specification and implementation in C can be found in this lovely detailed webpage. Right at the beginning of the theoretical explanation, the author is not shy of making it clear that it’s about data compression (and not necessarily linguistic representation):
Many compression algorithms replace frequently occurring bit patterns with shorter representations. The simple approach I present is to replace common pairs of bytes by single bytes.
The online presence of the author of the algorithm, Philip Gage, it’s a bit of a mystery: I couldn’t find anything else about him or his work other than BPE citations.
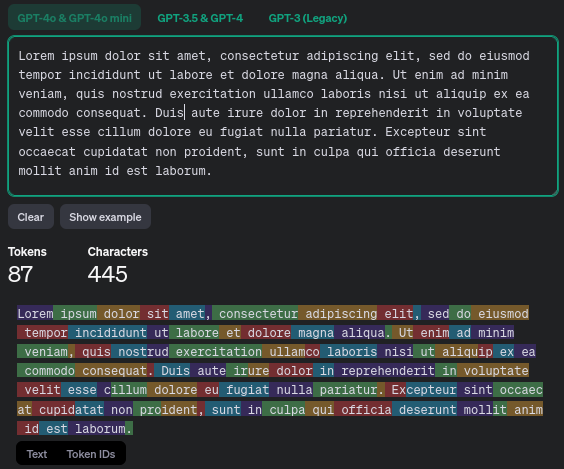
OpenAI’s implementation of it, tiktoken, can be used live in your web browser, check it out: platform.openai.com/tokenizer.
Other algorithms
Going into specifics of the algorithms goes beyond the scope of this introductory article, but it’s worth mentioning other tokenization algorithms as well, such as WordPiece (used by the BERT model), and Unigram (used by the T5 model), both by Google.