In this article, we will dive into how vector databases work, exploring Chroma and its underlying search library, hnswlib, along with understanding embeddings and embeddings models.
Most of the article will focus understanding things conceptually, what’s discussed here should help you understand how other vector database work too.
Since few might read this other than myself (right?), I’ll take the liberty to add a pinch of philosophy and linguistics before getting into the technical nitty-gritty.
Wittgenstein’s Philosophical Investigations (1953)

Ludwig Wittgenstein is an unique philosopher, and this doesn’t refer to the writing style of the Tractatus. He’s one of the few philosophers where there is not only a clear difference between his earlier and later work, but the ‘second stage’ Wittgenstein attempts to correct the first.
The first Wittgenstein tried to ground the logic of the world in the logic of language:
“the limits of my language are the limits of my world”
“whereof one cannot speak, thereof one must be silent”
He succeeded in doing so, helping lay the basis for an entire philosophical movement, analytical philosophy that is.
Later in life, Wittgenstein changed his views. In his philosophical investigations, he revised his ideas about language and meaning, concluding that meaning is situational and not a conclusion from some inherent logic of how language works:
“(…) The language is meant to serve for communication between a builder A and an assistant B. A is building with building-stones: there are blocks, pillars, slabs and beams. B has to pass the stones, and that in the order in which A needs them. For this purpose they use a language consisting of the words “block”, “pillar”, “slab”, “beam”. (…) Because if you shout “Slab!” you really mean: “Bring me a slab”
In the famous example above, there is a small language game between builder A and assistant B, consisted of just four words (or tokens), ‘slab’ being of them. It’s a fully functional language, the context (two builders working together) are the glue which makes it works.
The meaning it’s derived from what’s around the words, not the words itself.
Zelig Harris’ Distributional Structure (1954)

While not necessarily directly influenced by Wittgenstein, but in tandem with his ideas, the linguistic Zelig Harris writes:
“Meaning is not a unique property of language, but a general characteristic of human activity. (…) And if we consider the individual aspects of experience, the way a person’s store of meanings grows and changes through the years while his language remains fairly constant, or the way a person can have an idea or a feeling which he cannot readily express in the language available to him, we see that the structure of language does not necessarily conform to the structure of subjective experience, of the subjective world of meanings.”
Following along the same article, he highlights the importance of relative frequency (rather than linguistic rules) of word occurrences:
“there are many sentence environments in which oculist occurs but lawyer does not: e.g. ‘I’ve had my eyes examined by the same oculist for twenty years’, or ‘Oculists often have their prescription blanks printed for them by opticians’. It is not a question of whether the above sentence with lawyer substituted is true or not; it might be true in some situation. It is rather a question of the relative frequency of such environments with oculist and with lawyer (…)”
And later concludes and emphasizes how meaning arises from usage and frequency in language, and not from fixed predetermined rules:
“we cannot directly investigate the rules of ’the language’ via some system of habits or some neurological machine that generates all the utterances of the language. We have to investigate some actual corpus of utterances, and derive therefrom such regularities (…)”
John R. Firth’s Studies in Linguistic Analysis (1957)

John Rupert Firth, another influential linguist, echoed Wittgenstein’s approach to meaning:
“As Wittgenstein says, ’the meaning of words lies in their use.’ The day-to-day practice of playing language games recognizes customs and rules. It follows that a text in such established usage may contain sentences such as ‘Don’t be such an ass!’, ‘You silly ass!’, ‘What an ass he is!’ In these examples, the word ass is in familiar and habitual company, commonly collocated with you silly—, he is a silly—, don’t be such an—. You shall know a word by the company it keeps!”
The last statement of the citation in particular, “you shall know a word by the company it keeps”, became a motto for this idea. Firth’s emphasis on collocation (companion words) became a key concept in corpus linguistics and computational language analysis.
Word embeddings with word2vec (2013)

Word2Vec was the seminal embedding model developed by Tomas Mikolov and team at Google in 2013. It was revolutionary because it demonstrated how the meanings of words can be captured by dense vectors, where most elements are non-zero. After training the model, one could perform algebra-like operations on the vectors and get ‘semantic results’, like the well-known example of approximating the vector for the word “queen” by performing the calculation “king - man + woman”.
It offered two distinct ways to train a model: Continuous Bag of Words (CBOW) and Skip-gram. In CBOW, the model is given surrounding context words and attempts to predict the target word in the middle, such as predicting “like” in the sentence “I ___ candy”. In contrast, the Skip-gram model takes a target word (“like”) and tries to predict its surrounding words (“I” and “candy”).
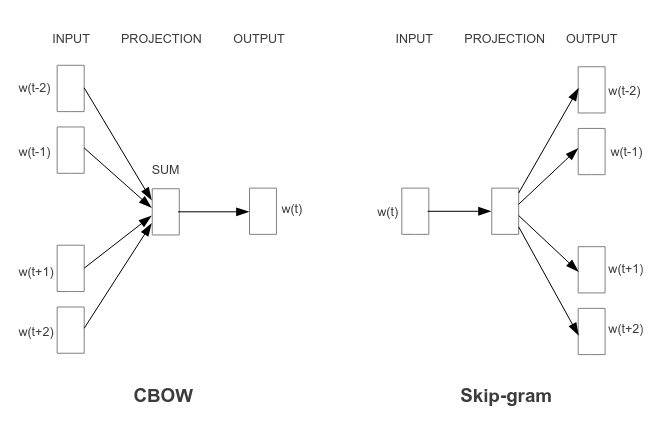
The model’s vocabulary is created by extracting all unique words from a corpus of texts. Words are ordered from most frequent to least frequent. Infrequent words are dropped (words below a frequency threshold). High-frequency words (like stop words) may be downsampled to reduce their dominance in the training process.
After the model is trained (either with CBOW or Skip-gram), we can forward pass each word into the network, get a resulting vector, and build a lookup table with it (where the key is the word and the value the dense vector). That essentially caches the produced embeddings by the model and allows an application that wants to use such embeddings to just look it up in the table. In other words, you can refer directly to this embedding matrix to get its embeddings, avoiding a forward pass to be performed on the actual model.
Let’s see it in action with the gensim package:
from gensim.downloader import load # pip install gensim
model = load('word2vec-google-news-300') # downloads 1.7 GB to ~/gensim-data
def display_similar_word(input_word):
similar_words = model.most_similar(input_word)
print(f'Similar words for "{input_word}":')
for word, similarity in similar_words:
print(f'• {word} ({similarity})')
print()
display_similar_word('spaghetti')
display_similar_word('mario')
# Similar words for "spaghetti":
# • pasta (0.6603320837020874)
# • ziti (0.6336025595664978)
# • rigatoni (0.6329466700553894)
# • Spaghetti (0.6238144636154175)
# • meatball_dinner (0.5845874547958374)
# • meatball_supper (0.5811535120010376)
# • spaghetti_noodles (0.5772687792778015)
# • linguine (0.5770878195762634)
# • fusilli (0.5688321590423584)
# • homemade_meatballs (0.5670261979103088)
# Similar words for "mario":
# • zelda (0.6978971362113953)
# • ps2 (0.6641138195991516)
# • nintendo (0.6476219296455383)
# • super_mario (0.6462492942810059)
# • psp (0.6432690620422363)
# • ps1 (0.6347845196723938)
# • ricky (0.626514732837677)
# • gamecube (0.6250814199447632)
# • naruto (0.6235296726226807)
# • lol (0.6227648258209229)
Subword embeddings with FastText (2016)

Three years after word2vec, Tomas Mikolov and his colleagues at Facebook developed FastText, a new embedding technique similar to word2vec, but this time working with subwords. Instead of treating each word as a token, FastText breaks words down into character-based n-grams, typically ranging from 3-grams to 6-grams, and creates embeddings from these n-grams.
FastText can generalize meanings for unseen words during training, as long as those words are composed of known n-grams.
Document embeddings with contemporary models (like OpenAI’s Ada)

Building on earlier, simpler embedding models, modern embeddings are more complex and are trained to operate on entire sequences of text, such as paragraphs or entire documents. The simple lookup in an embedding matrix is no longer sufficient. Instead, embeddings are generated through a forward pass in transformer-based models, which uses mechanisms like attention to produce contextualized embeddings.
Despite the complexity involved in training and generating those embeddings, the same distance and similarity principles of word embeddings apply to sentence-level embeddings as well. This means that semantic relationships can still be inferred based on the proximity of vectors in the vector space, allowing for meaning to be inferred through calculating vector distances.
Let’s see in practice how to generate embeddings. With OpenAI’s model:
from openai import OpenAI # pip install openai
input_text = 'Hello world!'
# assumes that OPENAI_API_KEY environment variable is set
client = OpenAI()
response = client.embeddings.create(model='text-embedding-ada-002', input=input_text)
embedding = response.data[0].embedding
print(f'Input: {input_text}')
print(f'Dimensions: {len(embedding)}')
print(f'Values: {str(embedding)[:50]}...')
# Input: Hello world!
# Dimensions: 1536
# Values: [0.006591646, 0.0036574828, -0.011824708, -0.02684...
With Google’s Gemini:
from google.generativeai import embed_content # pip install google-generativeai
input_text = 'Hello world!'
# assumes that GEMINI_API_KEY environment variable is set
response = embed_content(model='models/text-embedding-004', content=input_text)
embedding = response['embedding']
print(f'Input: {input_text}')
print(f'Dimensions: {len(embedding)}')
print(f'Values: {str(embedding)[:50]}...')
# Input: Hello world!
# Dimensions: 768
# Values: [0.00550769, -0.0112438, -0.06099073, -0.008677562...
Locally with Ollama:
from ollama import embeddings # pip install ollama
input_text = 'Hello world!'
# assumes that the model was pulled before hand (ollama pull nomic-embed-text)
response = embeddings(model='nomic-embed-text', prompt=input_text)
embedding = response['embedding']
print(f'Input: {input_text}')
print(f'Dimensions: {len(embedding)}')
print(f'Values: {str(embedding)[:50]}...')
# Input: Hello world!
# Dimensions: 768
# Values: [0.12398265302181244, -0.0613756962120533, -3.9841...
Finding related embeddings with K-Nearest Neighbors
As the philosophers and linguistics have alluded, and as the embedding models have shown mathematically, meaning comes from the surrounding text. But how do we make use of embeddings?
Similarity search. Similar embeddings (in meaning) should be collocated in the vector space, in other words, they should be closer together in the Euclidian space.
Enter K-Nearest Neighbors algorithm, or KNN for short: given a point in space (the vector in hand), find the K closest neighbors (where K is an user-defined value, such as 3 or 35).
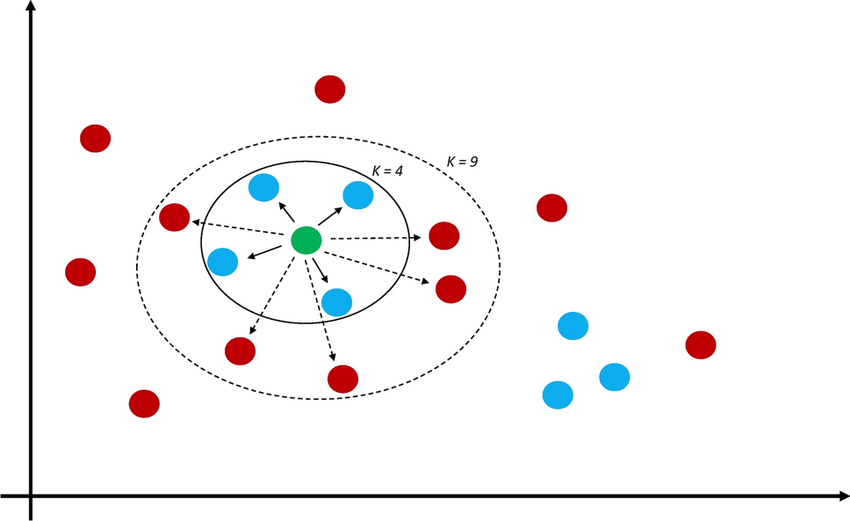
Searching for embeddings based on distance can serve as a replacement for traditional full-text search. Instead of relying on morphological operations like lemmatization or calculating levenshtein distance, we can match semantically meaningful (neighboring) words/chunks/documents.
Unfortunately, a non-optimized method for computing KNN is rather inefficient: it involves calculating the distance against all vectors before selecting the nearest.
It’s a small world, Isn’t It?
There’s no shame in quoting Wikipedia:
“A small world network is a graph characterized by a high clustering coefficient and low distances.”
In other words, in a small world network, any two randomly chosen nodes will have a short connecting path between them. These short paths are what make the network ‘small’.
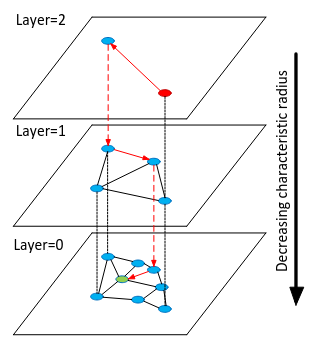
Hierarchical Navigable Small World (HNSW) is an algorithm, officially implemented as the hnswlib library, that addresses the previously mentioned performance issue by making a stack of many interconnected small worlds.
Instead of organizing all vectors in a flat space, HNSW structures them into multiple layered “small worlds.” Each layer is a subset of the vectors, forming its own graph where nodes (vectors) are connected to their nearest neighbors that layer. Additionally, each node is also linked vertically to nodes in the layer below, allowing the algorithm to navigate horizontally and vertically to find its target.
As a side note, small world networks not only apply to computing but also to social sciences. Ever heard of the “six degrees of separation idea”? That is the concept that all people are six or fewer social connections away from each other (‘friend of a friend’).
Storing and retrieving embeddings with Chroma

Let’s explore how to store and query embeddings using Chroma, one of the simplest vector databases available at the time of writing.
To begin, we’ll set up Chroma and create an empty database. The process is simple using Python:
from chromadb import PersistentClient # pip install chromadb
from chromadb.utils.embedding_functions import OllamaEmbeddingFunction
client = PersistentClient()
ollama_embedding = OllamaEmbeddingFunction(model_name='nomic-embed-text', url='http://localhost:11434/api/embeddings')
collection = client.get_or_create_collection(name='runescape_skills', embedding_function=ollama_embedding)
Next, we’ll embed data representing RuneScape skills into our Chroma database:
# taken from https://www.runescape.com/game-guide/skills
runescape_skills = {
'Agility': 'Improves run energy regeneration rate, as well as allowing access to shortcuts around the world.',
'Archaeology': 'Uncover lost knowledge that grants access to ancient summoning, ancient invention and relics that offer passive benefits whenever you play.',
'Attack': 'Improves your accuracy in Melee combat. Also allows the use of more powerful weapons.',
'Cooking': 'Allows fish and other food to be cooked on a fire or range. Higher levels allow better foods (that heal more life points) to be prepared.',
'Constitution': 'Increases your maximum amount of life points. Also unlocks several important combat abilities.',
'Construction': 'Allows the creation and improvement of a Player-Owned House. Higher levels allow the creation of more decorative furnishings and rooms.',
'Crafting': 'Allows the creation of a wide range of items such as jewellery, leather armour and battlestaves. Higher levels allow more items to be crafted.',
'Defence': 'Reduces the accuracy of opponents\' attacks from all styles and allows stronger armour to be equipped.',
'Divination': 'Gather the scattered divine energy of Guthix and weave it into powerful portents, signs, and temporary skilling locations.',
'Dungeoneering': 'Allows exploration of the randomly generated dungeons of Daemonheim. Higher levels allow deeper floors to be accessed.',
'Farming': 'Allows crops to be grown for use in other skills, notably herbs for Herblore. Higher levels allow more crop types to be grown.',
'Fishing': 'Allows fish - one of the main sources of food - to be retrieved from bodies of water. Higher levels allow more types of fish to be caught.',
'Firemaking': 'Allows fires to be built from logs. Higher levels allow more types of logs to be burnt.',
'Fletching': 'Allows the creation of bows, arrows, bolts and crossbows from logs. Higher levels allow more advanced items to be made.',
'Herblore': 'Allows the creation of potions from herbs, used to temporarily bestow a variety of different effects. Higher levels create more potent potions.',
'Hunter': 'Allows the trapping of various wild creatures using different methods. Higher levels allow more types of creature to be caught.',
'Invention': 'Customise your gear with cutting-edge augmentations. Invention is an Elite Skill, and requires 80 in Smithing, Crafting and Divination to begin training.',
'Magic': 'Increases accuracy - but not damage - of magic attacks. Allows more spells and better magical weapons and armour to be used. Also increases defence against magic attacks.',
'Mining': 'Allows ore to be obtained from rocks, for use in skills such as Smithing, Crafting and Invention, or to be sold. Higher levels allow rarer, more valuable types of ore to be mined.',
'Necromancy': 'Channel the power of necrotic energy and conjure powerful spirits to fight alongside you in combat.',
'Prayer': 'Grants access to modal buffs, which are useful in many areas of the game. Levelling unlocks new prayers, and allows prayers to stay active for longer.',
'Ranged': 'Increases the accuracy and damage of ranged attacks such as bows, throwing knives and crossbows. and allows the usage of better ranged weapons and armour.',
'Runecrafting': 'Allows the creation of runes for use in magic spells. Higher levels allow more rune types to be made, as well as multiple runes per essence.',
'Slayer': 'Allows otherwise-resilient creatures to be damaged, often using specialist equipment. Higher levels allow more powerful creatures to be slain.',
'Smithing': 'Allows metallic bars and items to be made from ore. Higher levels allow better items to be made from higher-level materials.',
'Strength': 'Improves your maximum hit in melee combat, increasing the amount of damage caused. Higher Strength is also a requirement to wield some weapons.',
'Summoning': 'Allows familiars to be summoned, which help in combat and other activities. Higher levels allow more powerful familiars to be summoned.',
'Thieving': 'Allows the player to steal from NPCs, disarm traps and open certain locked chests. Higher levels reduce failure rate and open up more lucrative targets.',
'Woodcutting': 'Allows trees to be cut down, producing logs for Fletching, Firemaking and Construction. Higher levels allow more types of trees to be cut down, yielding better logs.'
}
for name, description in runescape_skills:
collection.upsert(ids=name, documents=description)
And finally, let’s query it:
def display_results(results):
ids = results['ids'][0]
distances = results['distances'][0]
documents = results['documents'][0]
for i in range(len(ids)):
print(f'ID: "{ids[i]}"')
print(f'Distance: {distances[i]}')
print(f'Document:\n{documents[i]}')
print('\n--------------------\n')
query = 'Robbery is the crime of taking or attempting to take anything of value by force, threat of force, or by use of fear.'
query_results = collection.query(query_texts=query, n_results=3)
# Number of requested results 999 is greater than number of elements in index 29, updating n_results = 29
#
# ID: "Thieving"
# Distance: 337.1013233969683
# Document:
# Allows the player to steal from NPCs, disarm traps and open certain locked chests. Higher levels reduce failure rate and open up more lucrative targets.
#
#
# ID: "Prayer"
# Distance: 521.7312542572448
# Document:
# Grants access to modal buffs, which are useful in many areas of the game. Levelling unlocks new prayers, and allows prayers to stay active for longer.
As expected, the closest match is “Thieving” which is semantically related to robbery as both involve taking items unlawfully. However, if we examine the results more closely, we’ll see that even though the descriptions don’t share many words, embeddings capture the underlying semantic meaning. Take a look:
Robbery is the crime of taking or attempting to take anything of value by force, threat of force, or by use of fear.
Allows the player to steal from NPCs, disarm traps and open certain locked chests. Higher levels reduce failure rate and open up more lucrative targets.
Somewhat poetically, “Prayer” is the most distant vector from the robbery description (in our embeddings database).
Where to go next
Here are some topics to go beyond the basics:
- Hybrid search (embeddings + full text seach): Doing RAG? Vector search is not enough.
- Combining rankings from different search methods with RRF: Reciprocal Rank Fusion outperforms Condorcet and individual Rank Learning Methods.
- Plotting the embedding space with algorithms such as Principal Component Analysis (PCA), t-Distributed Stochastic Neighbor Embedding (t-SNE), Uniform Manifold Approximation and Projection (UMAP).
- Having more important information in earlier dimensions and less important in later dimensions: Matryoshka Embedding Models.
Alternatives
Some alternatives to Chroma (databases):
- Milvus
- Qdrant
- Weaviate
- Vespa
- Pinecone
- Redis (with RediSearch module)
- PostgreSQL (with pgvector extension)
- MongoDB (with Atlas Vector Search)
- Elasticsearch (with vector search)
And some alternatives search libraries (nearest neighbor implementation):
Sources
- The von Wright and Wittgenstein Archives (WWA)
- Ludwig Wittgenstein - Philosophical Investigations (1953)
- Zellig Harris: Language and Information
- Zellig S. Harris - Distributional Structure (1954)
- John Rupert Firth
- J. R. Firth - Studies in Linguistic Analysis (1957)
- Král − muž + žena = královna
- Efficient Estimation of Word Representations in Vector Space (2013)
- fastText
- Ada uses GPT-4 to deliver a new customer service standard
- ResearchGate - k-nearest neighbors
- Stanley Milgram - The Small-World Problem (1967)
- Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs (2016)
- Chroma
- Welcome to ChromaDB Cookbook
- Skills - RuneScape
- OpenAI Platform
- Model versions and lifecycle | Generative AI on Vertex AI | Google Cloud
- Embedding models · Ollama Blog