I’ve been playing LLMs locally and an acronym that is a usual suspect on documentation pages is “AVX”.
![]()

Advanced Vector Extensions is a SIMD extension to x86 architecture. Well, that’s what Wikipedia says anyway.
Let’s get into this rabbit hole and figure out how AVX relates to LLMs.
Single Instruction, Multiple Data (SIMD)
“Single Instruction, Multiple Data” is one of the best self-explanatory acronyms I’ve seen in a while! It’s pretty much what it says, performing a single instruction with a big set of registers:
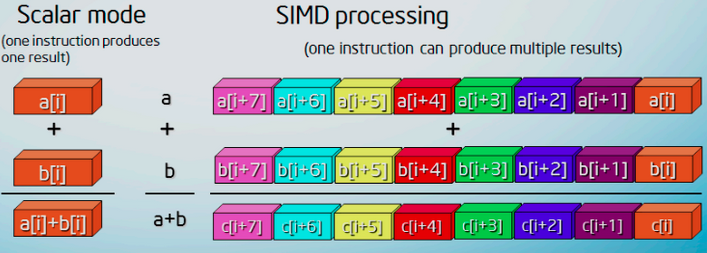
On the left side of the picture (orange boxes), we can see two scalar values being summed. On the right side (multi-colored boxes), due to SIMD, we can see two entire vectors of values being summed in “one shot” (in parallel).
Take a look at this handy diagram with the current registers of x86, and let’s focus on XMM, YMM, and ZMM registers (highlighted by me):
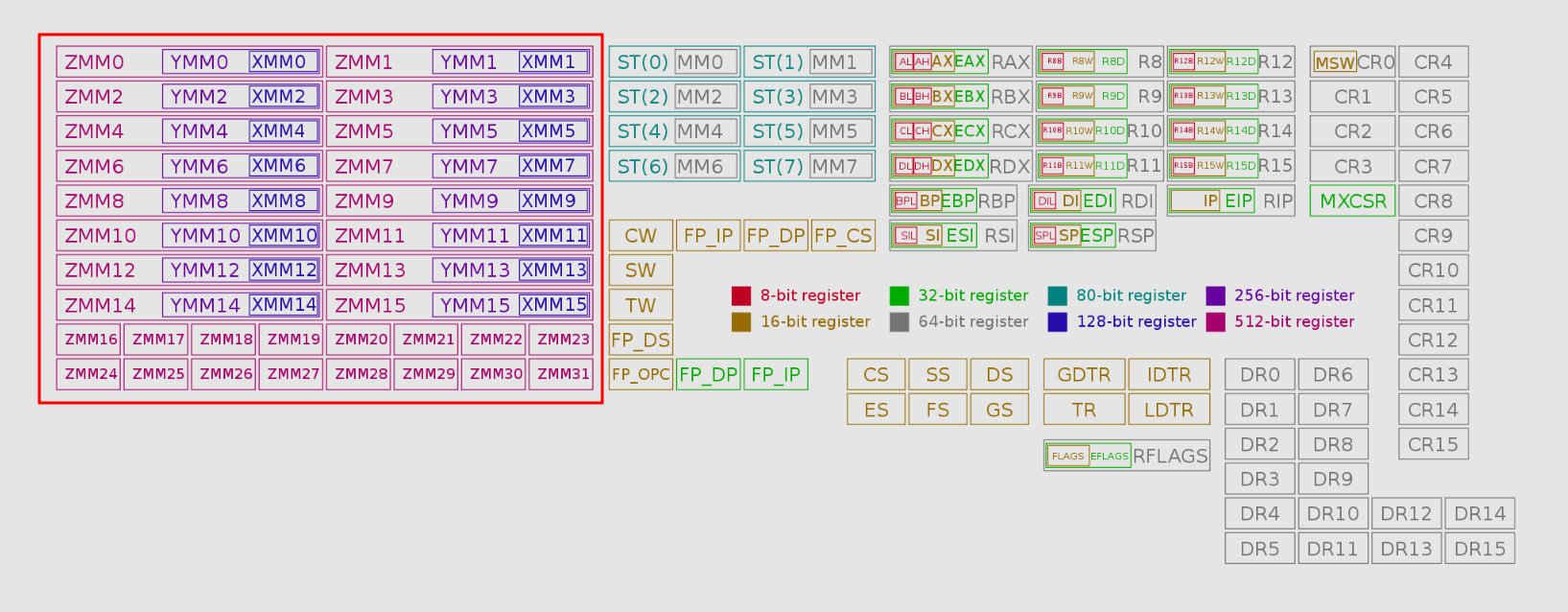
The XMM registers are 128-bit, which is the original AVX. AVX2 introduced YMM registers, which overlap with the XMM giving us 256-bit long registers. The latest AVX version, AVX-512, has increased yet again, to 512-bit now (ZMM registers).
Show me the code
Here is an example of summing vectors using GCC Vector Extensions:
#include <stdio.h>
#define LENGTH 4
typedef int v4si __attribute__ ((vector_size (LENGTH * sizeof(int))));
void print_vector(const v4si* vector) {
printf("{ ");
for(int i = 0; i < LENGTH; ++i) printf("%d ", (*vector)[i]);
printf("}");
}
int main() {
v4si a = {1, 2, 3, 4};
v4si b = {5, 6, 7, 8};
v4si c = a + b;
print_vector(&a);
printf(" + ");
print_vector(&b);
printf(" = ");
print_vector(&c);
printf("\n");
return 0;
}
Compiling it and executing it:
$ gcc -o vector_sum vector_sum.c
$ ./vector_sum
{ 1 2 3 4 } + { 5 6 7 8 } = { 6 8 10 12 }
A silly benchmark:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define LENGTH 4
typedef int v4si __attribute__ ((vector_size (LENGTH * sizeof(int))));
// Summing two scalar values per iteration
void regular_sum(const int *a, const int *b, int *c) {
for (int i = 0; i < LENGTH; ++i) {
c[i] = a[i] + b[i];
}
}
// Summing two vectors at once (no iteration)
void vector_extensions_sum(const v4si *a, const v4si *b, v4si *result) {
*result = *a + *b;
}
void benchmark(void (*func)(const void *, const void *, void *), const void *a, const void *b) {
const long long int ITERATIONS = 1000000000; // one billion
union { int int_c[LENGTH]; v4si vec_c; } throwaway_result;
clock_t start = clock(); // getting start time
for (long long int i = 0; i < ITERATIONS; ++i) func(a, b, &throwaway_result); // iterating a billion times
clock_t end = clock(); // getting end time
printf("%f seconds\n", ((double)(end - start)) / CLOCKS_PER_SEC);
}
int main() {
int a[LENGTH] = {1, 2, 3, 4};
int b[LENGTH] = {5, 6, 7, 8};
v4si va = {1, 2, 3, 4};
v4si vb = {5, 6, 7, 8};
printf("Regular sum: ");
benchmark((void(*)(const void *, const void *, void *))regular_sum, a, b);
printf("Vector extensions sum: ");
benchmark((void(*)(const void *, const void *, void *))vector_extensions_sum, &va, &vb);
return 0;
}
Here’s the numbers from my Ryzen 5 4600H:
$ gcc -o silly_benchmark silly_benchmark.c
$ ./silly_benchmark
Regular sum: 17.339803 seconds
Vector extensions sum: 2.371874 seconds
What about LLMs?
Since an LLM is just a bunch of neatly organized vectors, linear algebra (the study of vectors and linear functions) is essential for anything performed on it. Going further into this topic is beyond the scope of this article (and of my knowledge), but you can already imagine how we can save precious CPU cycles by doing calculations with vectors in “one shot” using AVX instructions.
But there’s only so much you can squeeze out from extending a processor architecture dating back to 1978. ‘Serious people’ use NVIDIA’s CUDA, AMD’s ROCm, or Intel’s oneAPI, but that’s another post for another day.