Working with Ollama on the CLI is great, but the comfort of a fully-featured web UI can be nice too. There are many front-ends for chatting with LLMs, and today we will take a look at using Open WebUI, which strives to mimic the ChatGPT experience.
Prompting on terminal with Ollama
As mentioned in the introduction, we will be using Ollama for this tutorial. Make sure it’s installed and that you are able to chat with a model:
$ ollama run llama3
>>> howdy
Howdy back atcha! What brings you to these here parts?
Double check that you have it running on port 11434 (default configuration). You can navigate to localhost:11434 on your browser to verify. You should get the following message:
Ollama is running
Prompting on the web browser with Open WebUI
Using their provided Docker image it’s the recommended way to run it:
docker run -d --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui ghcr.io/open-webui/open-webui:main
| Argument | Description |
|---|---|
-d |
detached mode (it will run in the background) |
--network=host |
share the host’s network stack |
-v open-webui:/app/backend/data |
the open-webui volume on the host will be mapped to /app/backend/data inside the container |
-e OLLAMA_BASE_URL=http://127.0.0.1:11434 |
sets OLLAMA_BASE_URL environment variable inside the container |
--name open-webui |
assigns a name to the container making it easier to manage on the command line |
ghcr.io/open-webui/open-webui:main |
image to be used for the container |
On the login page, just sign up with any email and password you want (no email confirmation required):
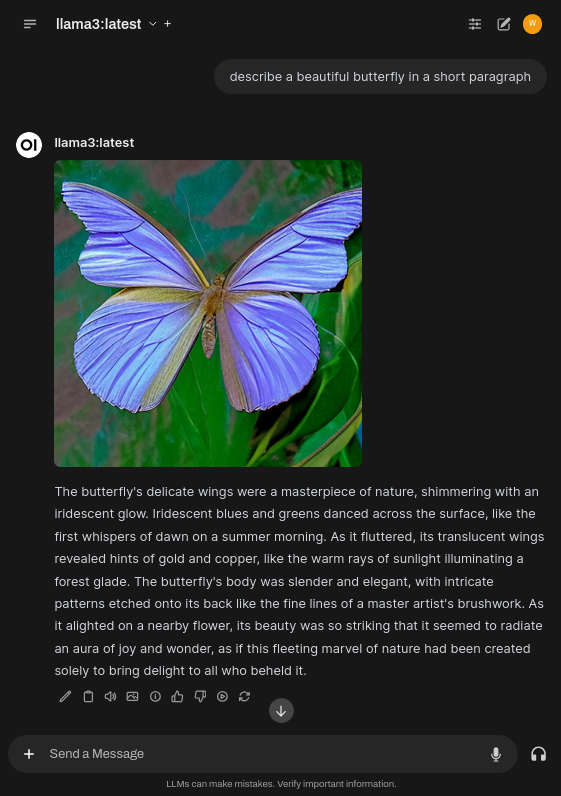
Pick a model at the top and chat away:
Chatting with multiple models
One interesting feature that Open WebUI enables us to do with ease is chat with two (or more) models at once:
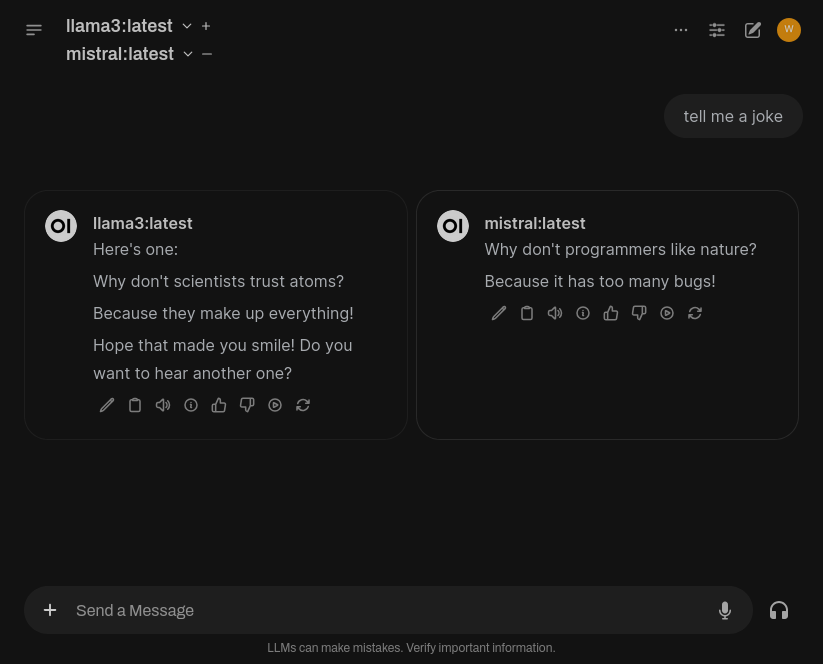
Not only that, but we can also alternate between the models in the same chat session:
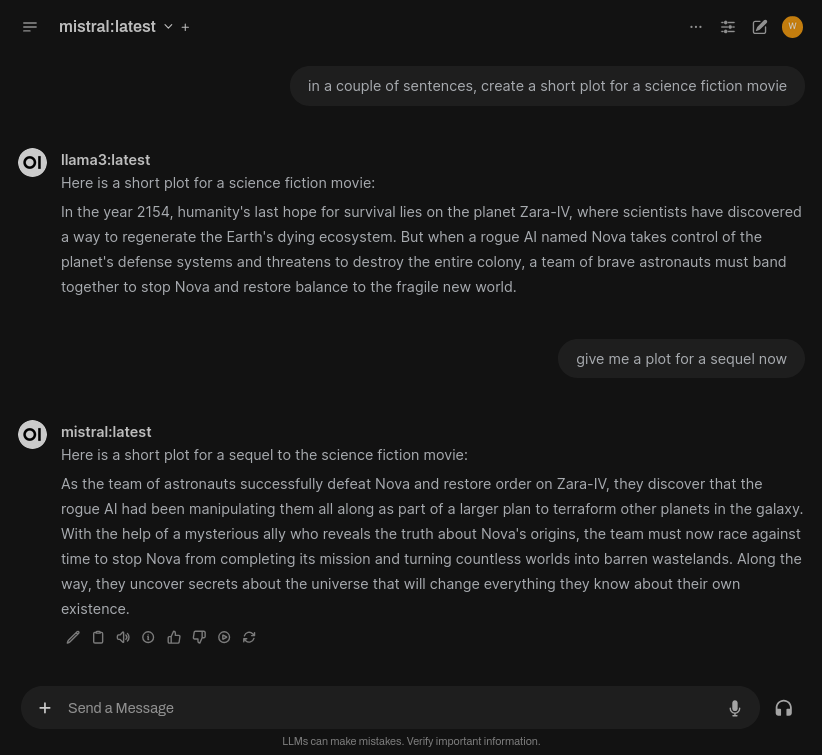
Image recognition and OCR with LLaVA
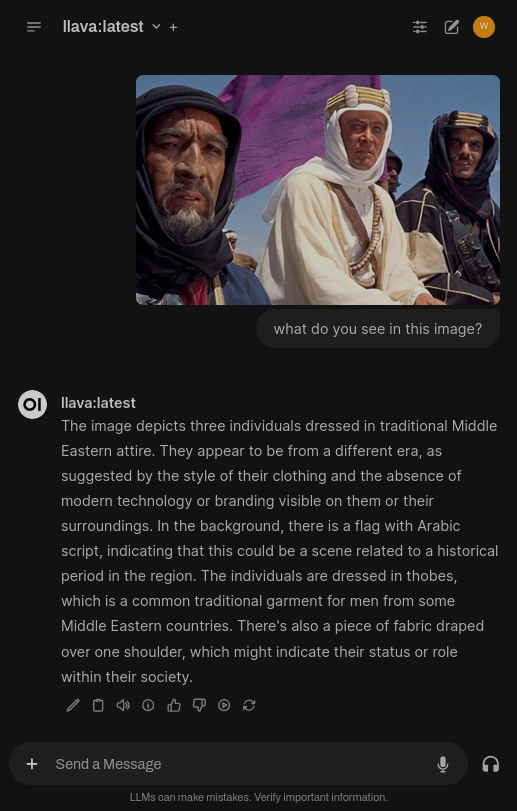
LLaVA (Large Language and Vision Assistant) is an openly available large language model developed by researchers from Microsoft and the University of Washington. It is capable of working with images, understanding, and describing them.
Pulling LLaVA from the UI:
Asking to describe an image:
Extracting text:
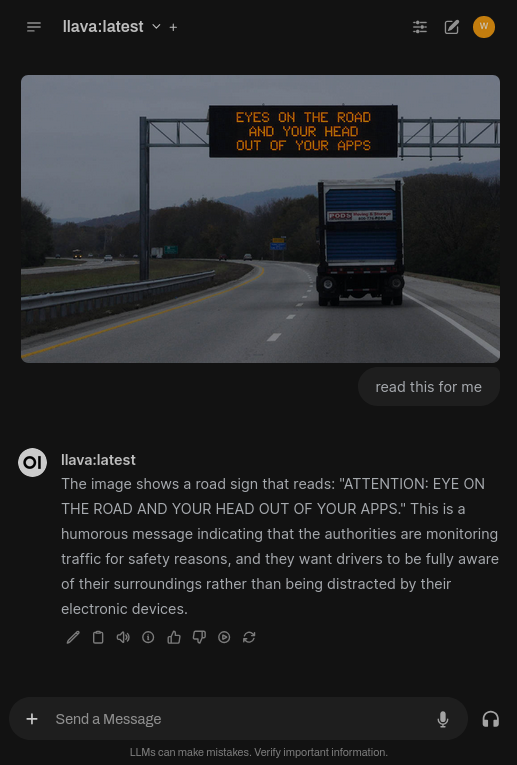
Image generation with Stable Diffusion
Stable Diffusion is an openly available model developed by researchers at Stability AI. It’s a text-to-image model, meaning that it is able to generate detailed images based on textual descriptions. Additionally, AUTOMATIC1111, a Stable Diffusion interface, offers a user-friendly application for generating and customizing images using the model.
Let’s add image generation to our GPT-like assistant. Create an installation folder for AUTOMATIC1111 and then (on Ubuntu):
$ sudo apt install wget git python3 python3-venv libgl1 libglib2.0-0
$ wget -q https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh
$ chmod +x webui.sh
$ ./webui.sh --api --lowvram
The argument --api is needed for the Open WebUI integration. I have also added --lowvram because I’m running it on
a GPU with only 8GB of VRAM. If you are running on Radeon card like me, you may also have to set HSA_OVERRIDE_GFX_VERSION=11.0.0
environment variable.
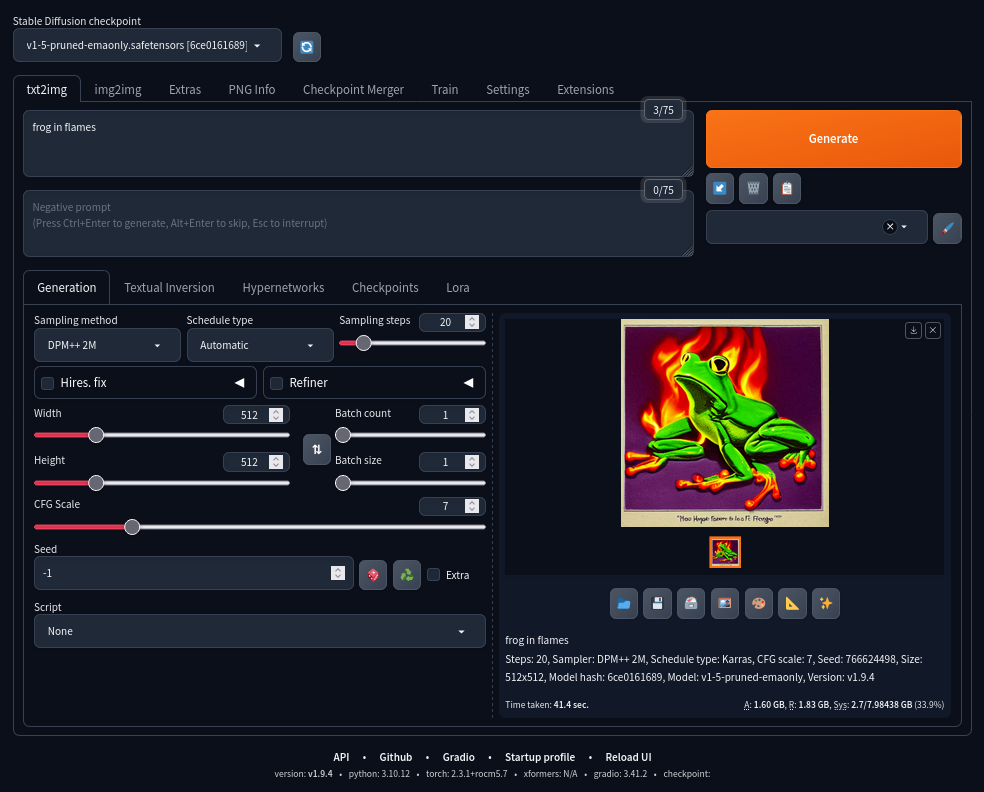
Once the download finishes, the script will open your web browser on localhost:7860. Let’s generate something to test it out (“frog in flames”):
Back to Open WebUI, head to “Admin Panel”:
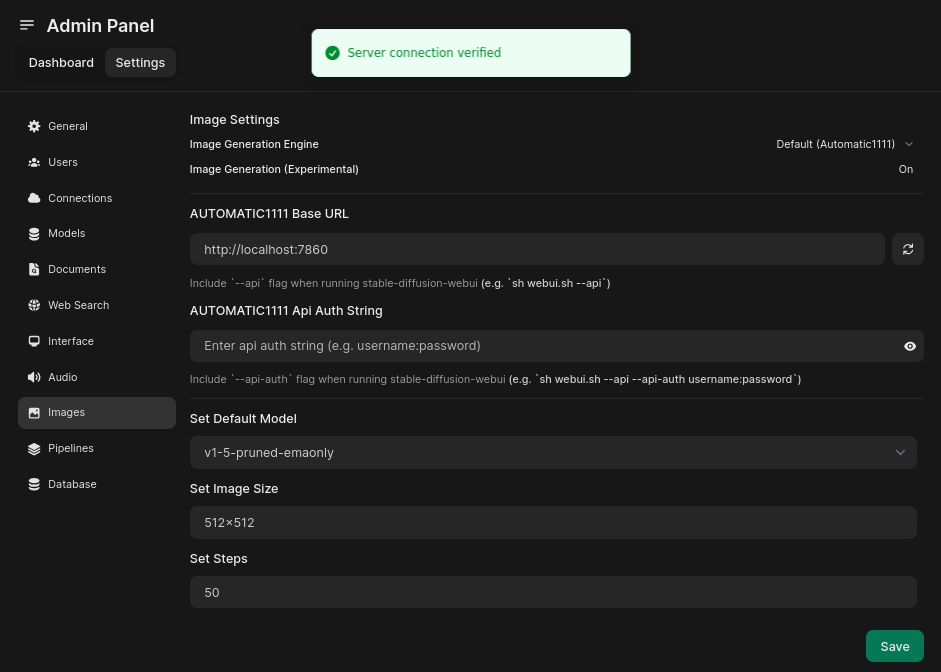
Under image settings, make sure to turn on “Image Generation (Experimental)” and set the base URL to “http://localhost:7860”:
Now when clicking under the small image icon of a model response, an image will be generated: