
When it comes to deep learning, choosing the right hardware is important. It’s not ideal for the job, but I already had a budget-friendly RX 7600 video card from AMD. While AMD video cards can be challenging to set up with deep learning tools, I’m pleased to report that the situation is improving.
Note that the RX 7600 is not officially listed in the ROCm (Radeon Open Compute) support list. Despite this, I managed to get everything up and running smoothly on Ubuntu 22.04.
Downloading and setting up drivers
First, let’s download the drivers from the AMD website and then install it:
$ sudo dpkg -i amdgpu-install_6.1.60103-1_all.deb
Next, set up the drivers for both “graphics” and “rocm” by running:
$ sudo amdgpu-install -y --usecase=graphics,rocm
It took a while, and almost 30GB of disk space occupied later, let’s add ourselves to the “render” and “video” groups:
sudo usermod -a -G render,video $LOGNAME
Finally, reboot the system:
sudo reboot
Checking GPU Usage
To make sure the GPU is working properly and to check its performance, we are going to install:
$ sudo apt install radeontop
$ sudo apt install xsensors
$ sudo apt install mesa-utils
Now let’s fire all of them (on different terminals) to see some GPU activity:
$ radeontop
$ xsensors
$ vblank_mode=0 glxgears -info
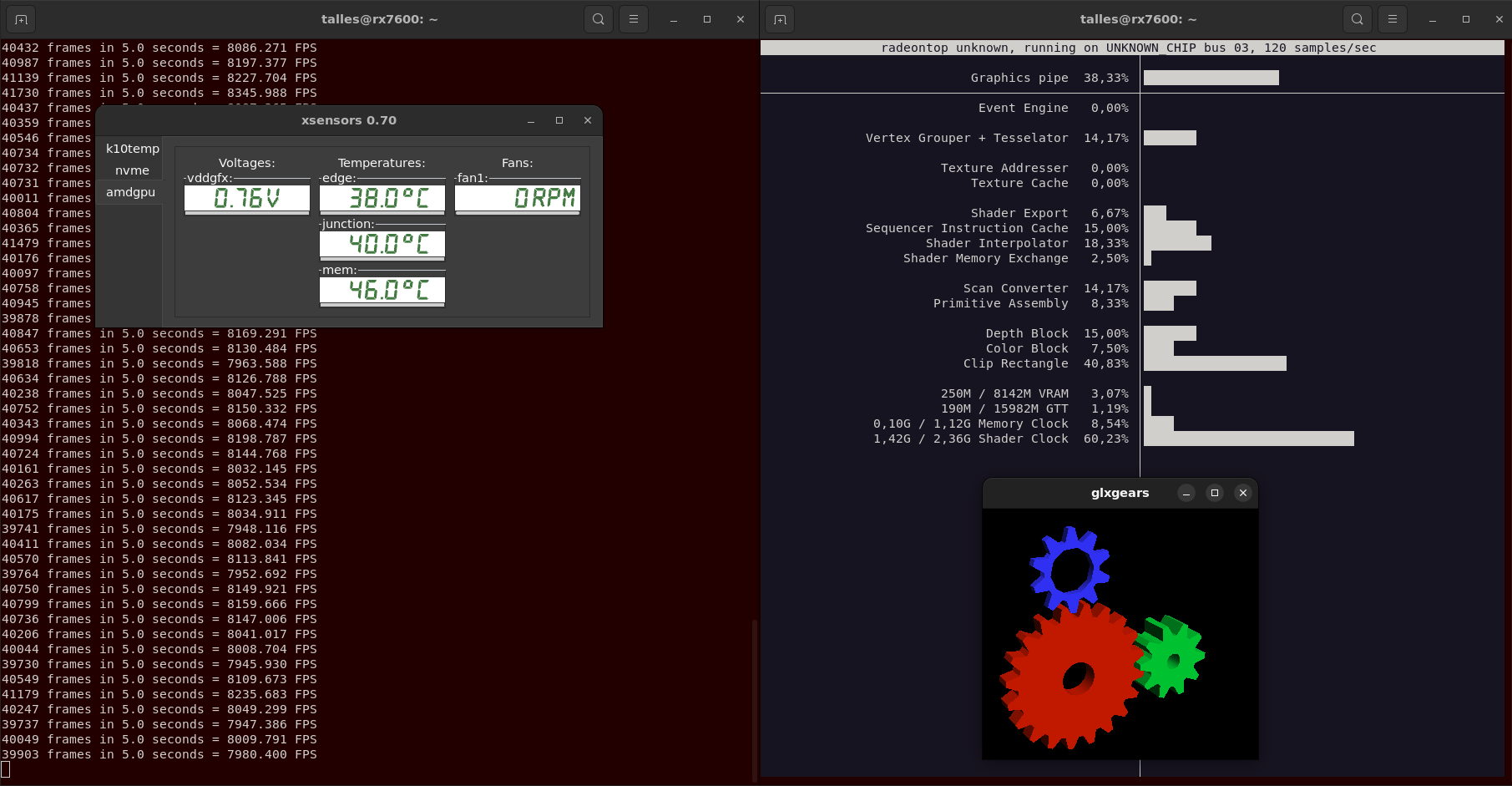
The “vblank_mode=0” variable disables vsync, allowing glxgears to run free from syncing it with the display refresh rate.
We can see activity on the GPU, but no spinning fan. Let’s try with glmark2:
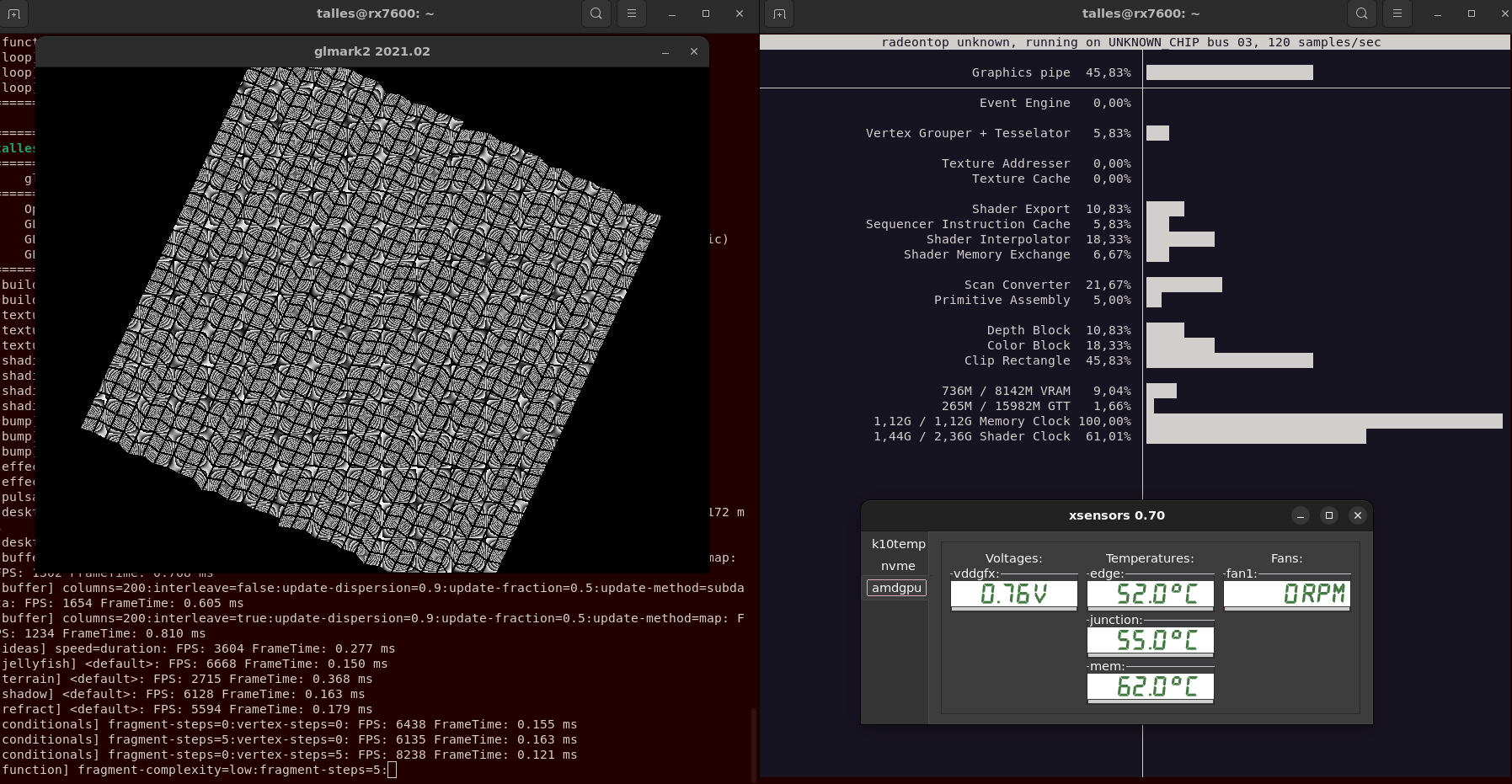
The fan is still idle. An AAA game did the trick, we can see the fan spinning now:
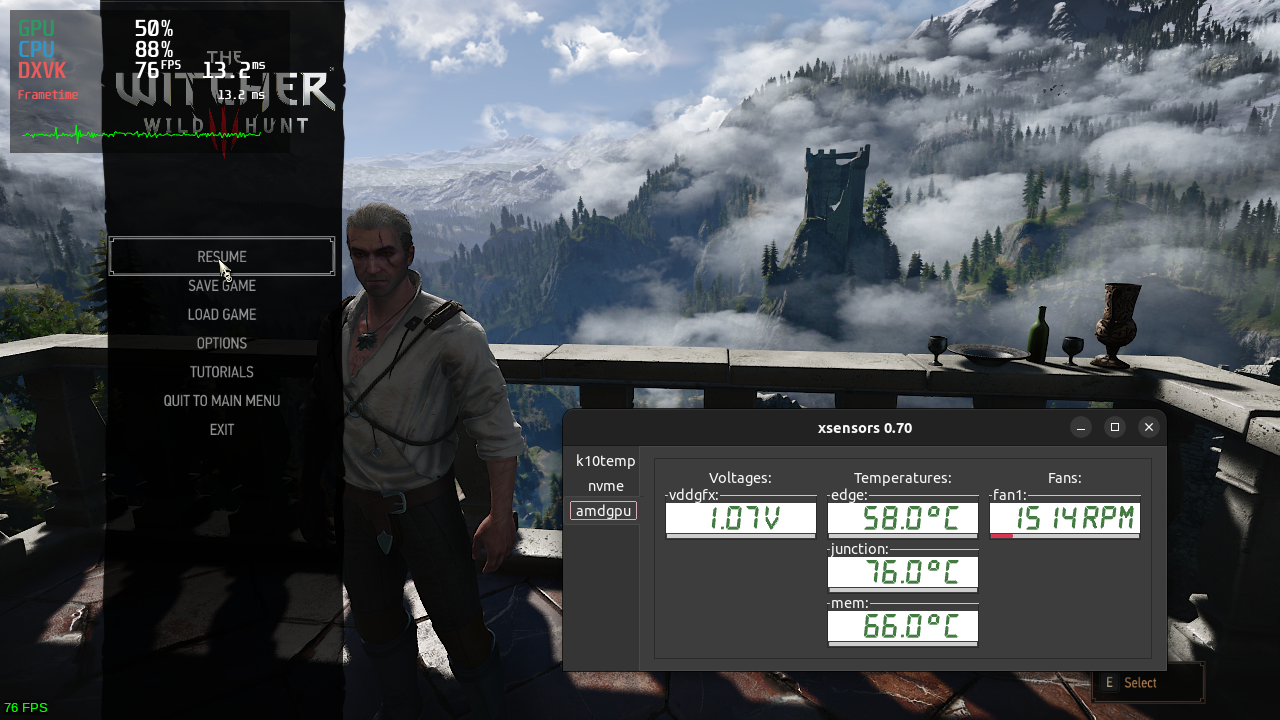
All good.
Ollama
Ollama recently announced support for AMD GPUs, and I’m glad to report that it worked flawlessly without custom configurations. We can see ~80 tokens/s with Gemma 2B:
$ ollama run gemma:2b --verbose
>>> tell me a story
The old clock tower stood sentinel over the bustling market square. Its weathered face bore the weight of countless stories, each tick and
tock telling a tale of its own. One sunny afternoon, a young woman named Luna decided to explore the tower and discover its secrets.
(...)
total duration: 4.531293086s
load duration: 1.650622ms
prompt eval count: 31 token(s)
prompt eval duration: 60.629ms
prompt eval rate: 511.31 tokens/s
eval count: 356 token(s)
eval duration: 4.333277s
eval rate: 82.15 tokens/s
PyTorch
To test if PyTorch will run on our GPU, the following script will generate a dummy load, confirming that our GPU is indeed being used by PyTorch:
import torch
import torch.nn as nn
import torch.optim as optim
def check_rocm_and_hip():
if torch.cuda.is_available() and torch.version.hip is not None:
print(f"ROCm is enabled. ROCm version: {torch.version.hip}")
return True
elif torch.cuda.is_available() and torch.version.hip is None:
print("ROCm is enabled but HIP runtime is not available.")
return True
else:
print("ROCm is not enabled.")
return False
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(10, 50)
self.fc2 = nn.Linear(50, 50)
self.fc3 = nn.Linear(50, 1)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
def generate_random_data(batch_size=32, device='cpu'):
inputs = torch.randn(batch_size, 10).to(device)
targets = torch.randn(batch_size, 1).to(device)
return inputs, targets
def train_indefinitely(device):
net = SimpleNet().to(device)
criterion = nn.MSELoss()
optimizer = optim.SGD(net.parameters(), lr=0.001)
iteration = 0
try:
while True:
inputs, targets = generate_random_data(device=device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
if iteration % 10000 == 0:
print(f"Iteration {iteration}, Loss: {loss.item()}")
iteration += 1
except KeyboardInterrupt:
print("Training interrupted. Exiting...")
if __name__ == "__main__":
device = 'cuda' if check_rocm_and_hip() else 'cpu'
train_indefinitely(device)
Trying it out:
$ python3 -m venv venv
$ source venv/bin/activate
(venv) $ pip install numpy torch --index-url https://download.pytorch.org/whl/rocm6.0
(venv) $ HSA_OVERRIDE_GFX_VERSION=11.0.0 python3 pytorch_rocm_test.py
ROCm is enabled. ROCm version: 6.0.32830-d62f6a171
Iteration 0, Loss: 0.8264276385307312
Iteration 10000, Loss: 0.982790470123291
Iteration 20000, Loss: 1.1837289333343506
(...)
It’s still unclear why it’s needed, but I could only make it work by setting up the environment variable “HSA_OVERRIDE_GFX_VERSION” first.
TensorFlow
Here’s the dummy load script using TensorFlow instead:
import tensorflow as tf
from tensorflow.keras import layers, models, optimizers, losses
def check_rocm_and_hip():
gpus = tf.config.list_physical_devices('GPU')
if gpus:
try:
for gpu in gpus:
details = tf.config.experimental.get_device_details(gpu)
if 'hip_version' in details:
print(f"ROCm is enabled. ROCm version: {details['hip_version']}")
return True
print("ROCm is enabled but HIP runtime is not available.")
return True
except RuntimeError as e:
print(f"Error in getting device details: {e}")
return False
else:
print("ROCm is not enabled.")
return False
class SimpleNet(models.Model):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = layers.Dense(50, activation='relu', input_shape=(10,))
self.fc2 = layers.Dense(50, activation='relu')
self.fc3 = layers.Dense(1)
def call(self, inputs):
x = self.fc1(inputs)
x = self.fc2(x)
x = self.fc3(x)
return x
def generate_random_data(batch_size=32):
inputs = tf.random.normal((batch_size, 10))
targets = tf.random.normal((batch_size, 1))
return inputs, targets
def train_indefinitely(device):
strategy = tf.distribute.get_strategy()
with strategy.scope():
net = SimpleNet()
net.build((None, 10))
criterion = losses.MeanSquaredError(reduction=losses.Reduction.SUM)
optimizer = optimizers.SGD(learning_rate=0.001)
iteration = 0
try:
while True:
inputs, targets = generate_random_data()
with tf.GradientTape() as tape:
outputs = net(inputs)
loss = criterion(targets, outputs)
grads = tape.gradient(loss, net.trainable_variables)
optimizer.apply_gradients(zip(grads, net.trainable_variables))
if iteration % 10000 == 0:
print(f"Iteration {iteration}, Loss: {loss.numpy()}")
iteration += 1
except KeyboardInterrupt:
print("Training interrupted. Exiting...")
if __name__ == "__main__":
device = '/GPU:0' if check_rocm_and_hip() else '/CPU:0'
with tf.device(device):
train_indefinitely(device)
Unfortunately, TensorFlow has been trickier than PyTorch, no matter what I tried I couldn’t make it work without resorting to AMD’s Docker image:
docker run -it --device=/dev/kfd --device=/dev/dri --group-add video -v "$PWD":/data -e HSA_OVERRIDE_GFX_VERSION=11.0.0 -e TF_CPP_MIN_LOG_LEVEL=1 rocm/tensorflow python3 /data/tensorflow_rocm_test.py